6 парсеров для ИИ-агентов в 2026: Crawl4AI, Firecrawl, Scrapy, Crawlee, Playwright и ScrapeGraphAI
Если нужно вытащить данные с сайта, старый вопрос “какой парсер лучше?” уже плохо работает. В 2026 году задача почти всегда звучит конкретнее: получить чистый Markdown для нейросети, собрать таблицу товаров, проверить страницу в настоящем браузере, обойти большой сайт или встроить сбор данных в ИИ-агента.
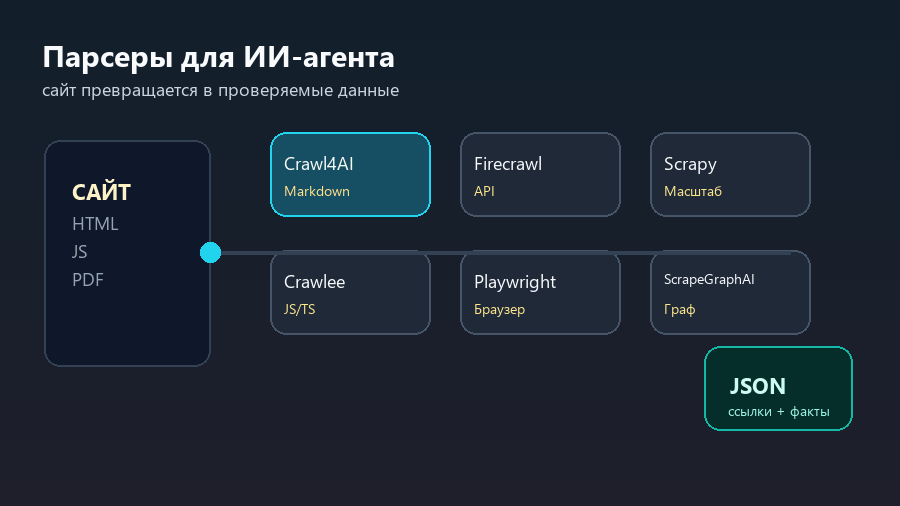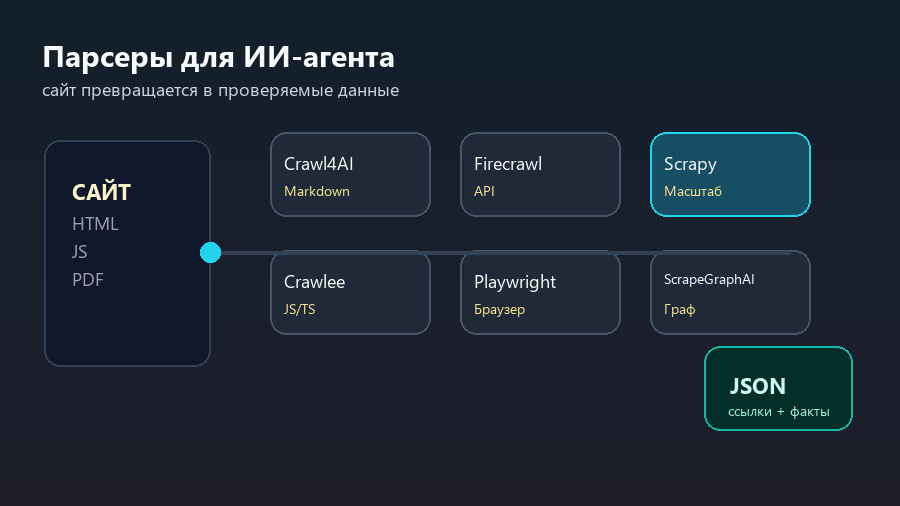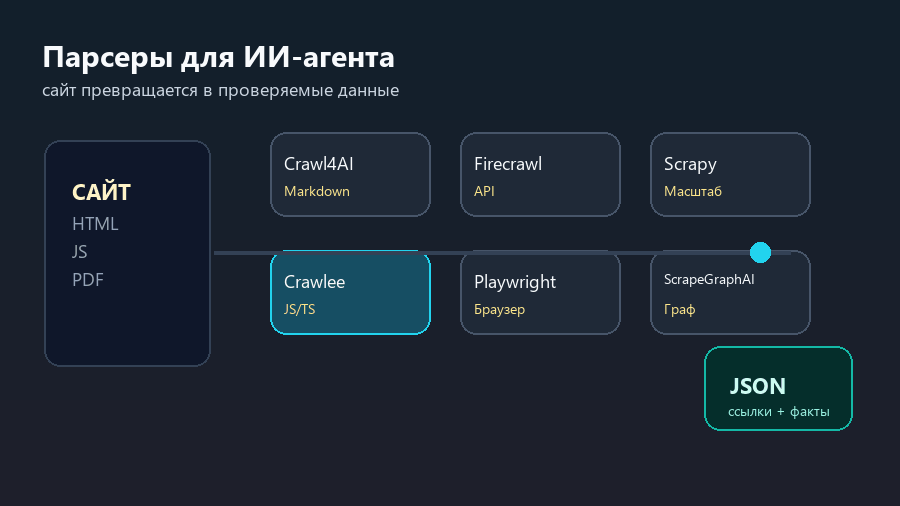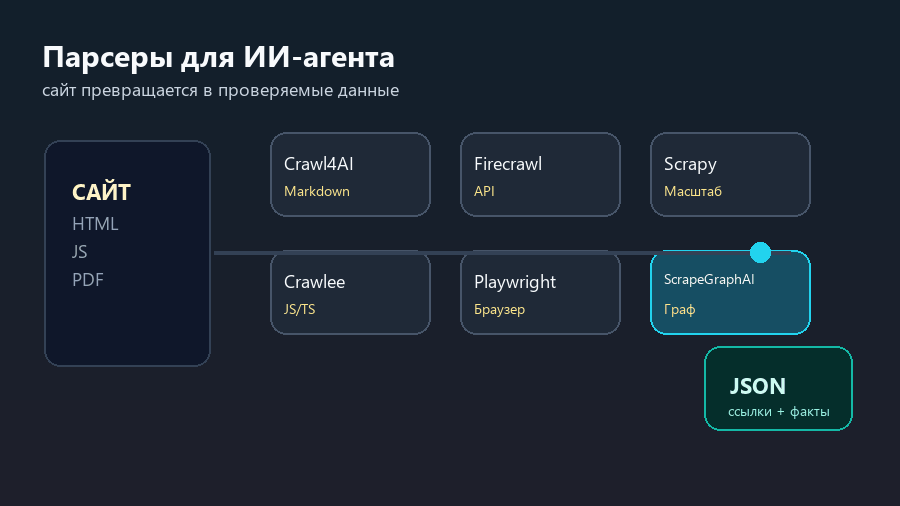
Поэтому правильный выбор начинается не с названия инструмента, а с результата. Crawl4AI и Firecrawl удобны, когда веб-страницу нужно превратить в материал для большой языковой модели. Scrapy и Crawlee сильнее там, где нужен управляемый сбор данных на масштабе. Playwright нужен, когда сайт раскрывается только в браузере. ScrapeGraphAI интересен как способ описывать сбор данных более смысловыми шагами.
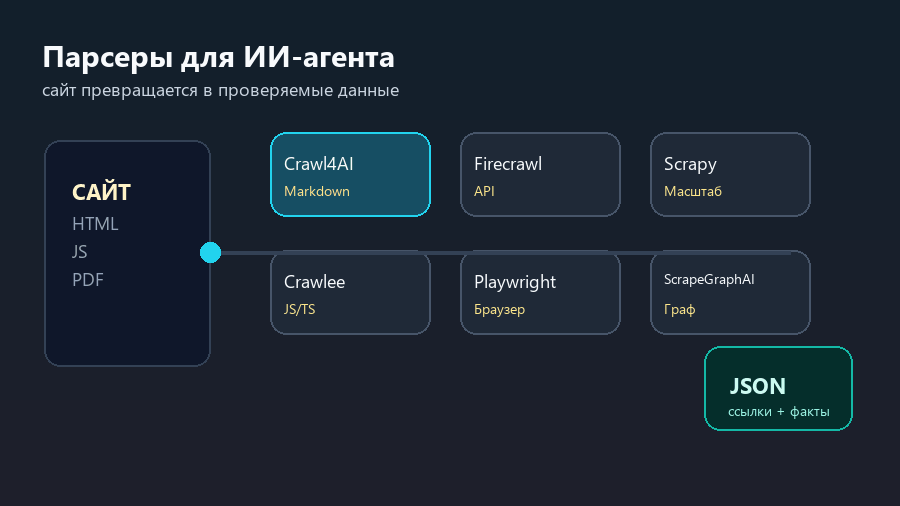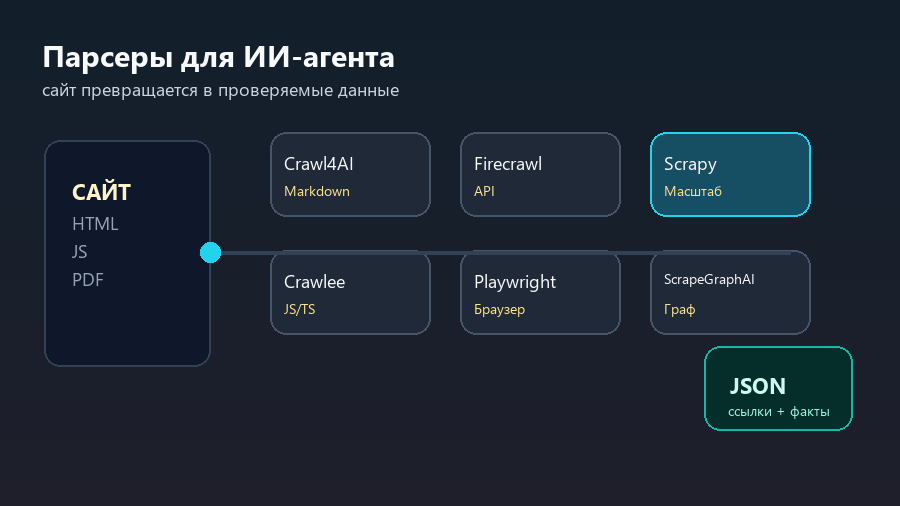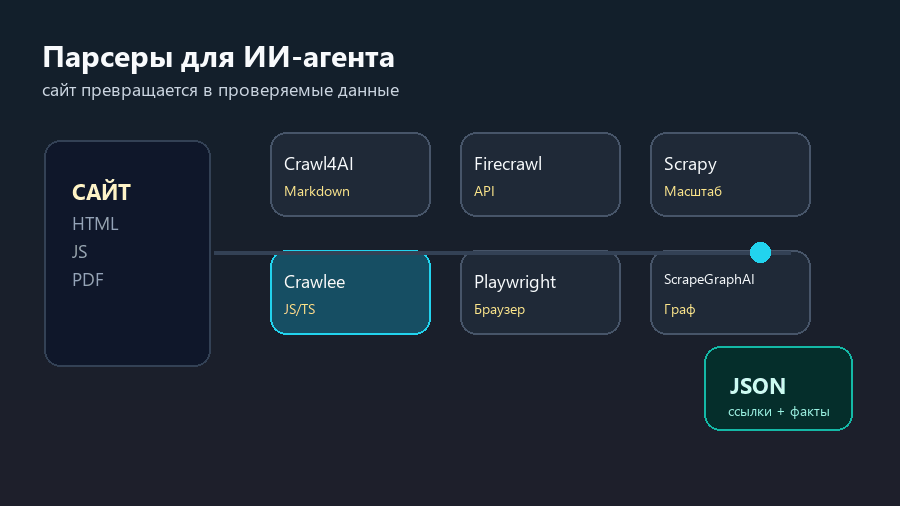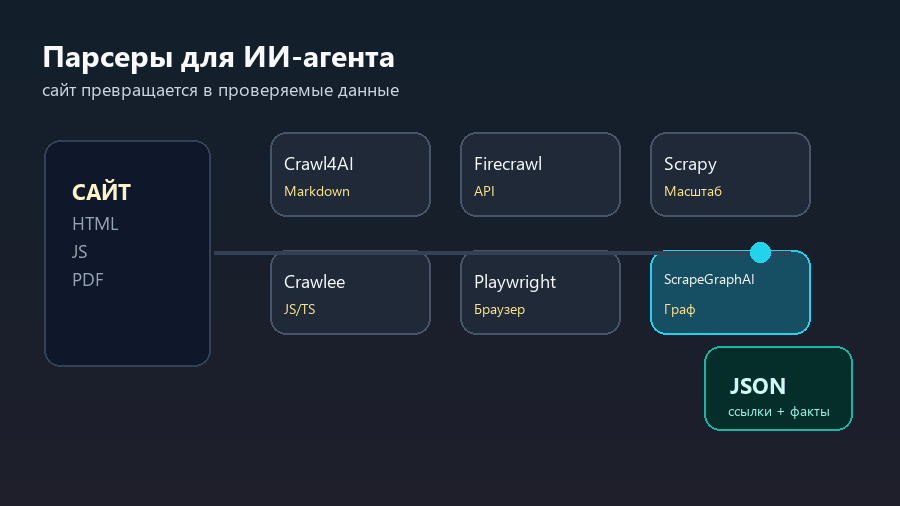
Короткий выбор
| Инструмент | Когда брать | Что получается | Где осторожно |
|---|---|---|---|
| Crawl4AI | Нужно быстро превратить сайт в текст для ИИ | Markdown, извлеченные блоки, материалы для базы знаний | Проект живой, поэтому важно фиксировать версию и проверять результат |
| Firecrawl | Нужен API для сайтов, карт сайта и страниц под LLM | Markdown, structured output, crawl/map/scrape-пайплайн | Цена, лимиты и качество зависят от режима использования |
| Scrapy | Нужен зрелый Python-краулер для больших задач | Пауки, очереди запросов, pipelines, exporters | Браузерный JavaScript придется подключать отдельно |
| Crawlee | Нужен современный краулер на JavaScript/TypeScript | Надежные crawlers, браузерные crawlers, очереди | Требует инженерной настройки, если задача не типовая |
| Playwright | Нужно открыть сайт как пользователь | Снимки, клики, формы, динамические страницы | Это не “парсер всего”, а браузерная автоматизация |
| ScrapeGraphAI | Нужно описывать извлечение данных как смысловой граф | LLM-ориентированный scraping pipeline | Нужно внимательно проверять точность и повторяемость |
Редакционный вывод: лучший парсер не тот, у которого больше функций, а тот, чей результат можно проверить и повторить.
Парсер теперь делает не только HTML
Классический парсинг был понятным: скачать HTML, найти элементы по селектору, сохранить данные. Это всё ещё нужно. Но когда поверх сайта работает ИИ-агент, появляется второй слой: агенту нужен не просто HTML, а аккуратные факты, ссылки, таблицы, заголовки, даты, цены, исключения и следы проверки.
Например, статья про AI-мониторинг интернета и Open Scouts как раз показывает эту смену логики. Агент не “читает интернет” магически. Он получает страницы, превращает их в удобный формат, сравнивает, сохраняет и потом возвращается к источникам.
Если это база знаний, чаще нужен чистый Markdown. Если это магазин, нужны поля и таблицы. Если это сайт с кнопками, всплывающими окнами и подгрузкой данных, без настоящего браузера не обойтись. Если это регулярный сбор, нужен журнал ошибок, повторные попытки и контроль изменений.
Crawl4AI и Firecrawl: когда сайт нужен нейросети
Crawl4AI стоит рассматривать, когда задача звучит так: “возьми сайт и подготовь его для нейросети”. Важный результат здесь не просто текст, а материал, который можно положить в поиск по документам, базу знаний или пайплайн генерации ответа. Для ИИ-агента это похоже на рабочее чтение: убрать шум, сохранить структуру, не потерять ссылки и смысловые блоки.
Firecrawl решает близкую задачу, но больше похож на готовый сервисный слой: scrape, crawl, map, structured extraction. Его удобно ставить там, где не хочется собирать всю инфраструктуру обхода самому. Поэтому Firecrawl часто оказывается рядом с агентами, которые мониторят сайты, собирают страницы конкурентов, обновляют внутренние справочники или готовят материалы для обзора.
Разница простая: Crawl4AI удобен как открытый инструмент в инженерной сборке, Firecrawl удобен как сервисный вход в веб-данные. Но оба инструмента нужно проверять не по красивому демо, а по тому, как они обрабатывают плохие страницы: длинные документы, таблицы, меню, дубли, рекламу, скрытый текст и обновления.
Scrapy и Crawlee: когда важен масштаб
Scrapy остается сильным выбором для Python-команд. Он хорош там, где есть много однотипных страниц, понятные правила обхода, выгрузка данных и длительный жизненный цикл проекта. Если нужно собрать каталог, новости, карточки, цены, документы или архив, Scrapy дает не “один скрипт”, а нормальную систему: пауки, pipelines, настройки, middleware и exporters.
Crawlee ближе к современному JavaScript/TypeScript-миру. Его логично брать, если команда уже живет в Node.js, если нужен headless-браузер, очереди запросов, прокси, повторные попытки и аккуратная работа с современными сайтами. Crawlee особенно хорошо ложится на задачи, где обычного HTTP-запроса мало, но писать всю механику браузера с нуля не хочется.
Для ИИ-агентов это важная пара. Агент может придумать, что искать, но регулярный сбор должен быть скучным и надежным. Scrapy и Crawlee как раз про это: меньше “вау”, больше контроля.
Playwright: когда сайт надо увидеть
Playwright часто ошибочно записывают в парсеры. Точнее сказать так: это инструмент, который открывает сайт как настоящий пользователь. Он умеет работать с Chromium, Firefox и WebKit, нажимать кнопки, ждать загрузки, заполнять формы, делать скриншоты и проверять интерфейс.
Если сайт отдает данные только после клика, входа, прокрутки или выполнения JavaScript, Playwright становится не роскошью, а необходимостью. Но использовать его как главный инструмент для всего подряд дорого: браузер тяжелее обычного HTTP-запроса, медленнее и требует больше контроля.
В связке с ИИ-агентом Playwright хорош как “глаза и руки”. Агент может проверить, как выглядит результат, открыть страницу, нажать фильтр, скачать файл, сделать скриншот. А уже после этого данные можно передать в более дешевый слой обработки.
ScrapeGraphAI: когда сбор данных описывается смыслом
ScrapeGraphAI интересен не как замена всем парсерам, а как другой способ думать о задаче. Вместо набора жестких селекторов появляется граф шагов: что найти, как понять страницу, что извлечь, как вернуть результат. Это ближе к тому, как человек объясняет задачу помощнику.
Плюс очевиден: можно быстрее собирать прототипы для нестандартных страниц. Минус тоже очевиден: чем больше в пайплайне смысловой интерпретации, тем важнее проверка. Для финансовых, юридических, медицинских и договорных данных нельзя полагаться только на “модель поняла”. Нужны контрольные примеры, сверка с источником и сохранение исходной ссылки.
Здесь полезно вспомнить статью про навыки ИИ-агентов и SkillOpt. Хороший агент не просто выполняет задачу, а оставляет проверяемый след: что открыл, что извлек, что не понял, где нужна ручная проверка.
Практическая схема выбора
Что проверять перед внедрением
| Задача | Первый выбор | Почему |
|---|---|---|
| Подготовить сайт для базы знаний | Crawl4AI или Firecrawl | Они сразу думают в сторону Markdown и LLM-friendly данных |
| Регулярно собирать каталог или архив | Scrapy или Crawlee | Есть контроль обхода, повторные попытки и нормальная инженерная структура |
| Проверить страницу как пользователь | Playwright | Он видит динамический интерфейс, клики и состояние браузера |
| Быстро собрать прототип извлечения | ScrapeGraphAI | Можно описывать цель более смысловым способом |
| Делать мониторинг интернета агентом | Firecrawl плюс свой контроль | Удобно отдавать агенту чистые страницы и сохранять источник |
У любого парсера есть один общий риск: он может уверенно вернуть неполные данные. Поэтому перед тем как ставить инструмент в рабочий процесс, стоит проверить несколько вещей.
Во-первых, как он ведет себя на “грязных” страницах: баннеры, меню, карточки, бесконечная прокрутка, таблицы, PDF-ссылки, старые шаблоны. Во-вторых, как он сохраняет адрес источника и дату доступа. В-третьих, можно ли повторить результат через неделю. В-четвертых, есть ли режим, где человек быстро видит ошибку, а не узнает о ней из сломанного отчета.
Если парсер работает для статьи, обзора или внутренней базы знаний, можно допустить ручную проверку. Если он работает для коммерческого мониторинга, цен, документов или юридически значимых данных, нужен отдельный слой контроля: журнал запусков, выборочная сверка, алерты и правила исключений.
FAQ
Что выбрать для ИИ-агента?
Если агенту нужно читать сайты и возвращать текстовые ответы, начните с Crawl4AI или Firecrawl. Если агент должен нажимать кнопки и проверять интерфейс, добавьте Playwright. Если задача станет регулярной и большой, переносите сбор в Scrapy или Crawlee.
Можно ли всё делать Playwright?
Технически часто можно, но это не всегда разумно. Playwright тяжелее и медленнее обычного парсинга. Его лучше использовать там, где реально нужен браузер: JavaScript, формы, авторизация, клики, скриншоты и визуальная проверка.
Почему Markdown так важен для ИИ?
Большой языковой модели легче работать с текстом, где сохранены заголовки, списки, таблицы и ссылки. Поэтому инструменты, которые сразу превращают сайт в чистый Markdown, сокращают путь от страницы к ответу.
Как не ошибиться?
Сначала определите не инструмент, а проверяемый результат: какие поля нужны, где хранится источник, как выглядит ошибка и кто принимает решение, если данные неполные. Тогда выбор парсера становится инженерным, а не вкусовым.